redshift unload to s3|Unloading a file from Redshift to S3 (with headers) : Manila You can unload the result of an Amazon Redshift query to your Amazon S3 data lake in Apache Parquet, an efficient open columnar storage format for analytics. In .
Manila, Mexico City, and Madrid are considered the world's original set of global cities because Manila's commercial networks were the first to extend across the Pacific Ocean and connect Asia with the Spanish Americas. When this was accomplished, it marked the first time in world history that an uninterrupted chain of trade routes circling the .
redshift unload to s3,You can unload the result of an Amazon Redshift query to your Amazon S3 data lake in Apache Parquet, an efficient open columnar storage format for analytics. Parquet .
unload ('select * from venue') to 's3://amzn-s3-demo-bucket/unload/' iam_role .
Amazon Redshift splits the results of a select statement across a set of files, .Amazon Redshift splits the results of a select statement across a set of files, one or more files per node slice, to simplify parallel reloading of the data. Alternatively, you can .unload ('select * from venue') to 's3://amzn-s3-demo-bucket/unload/' iam_role 'arn:aws:iam::0123456789012:role/MyRedshiftRole'; By default, UNLOAD writes one or . You can unload the result of an Amazon Redshift query to your Amazon S3 data lake in Apache Parquet, an efficient open columnar storage format for analytics. In .
The ability to unload data natively in JSON format from Amazon Redshift into the Amazon S3 data lake reduces complexity and additional data processing steps if that data needs to be ingested into .
A few days ago, we needed to export the results of a Redshift query into a CSV file and then upload it to S3 so we can feed a third party API. Redshift has already an UNLOAD command that.
Following are the two methods that you can follow to unload your data from Amazon Redshift to S3: Method 1: Unload Data from Amazon Redshift to S3 using the UNLOAD command; Method 2: .With Redshift we can select data and send to data sources available to us in AWS Cloud. Data sources like RDS, Athena, or S3. With the UNLOAD command, we can save files .
I've been trying to unload some data from Redshift to the S3 bucket. Except I've been getting the following error: Amazon Invalid operation: cannot drop active portal; .I'm trying to unload data from my Amazon Redshift cluster to Amazon Simple Storage Service (Amazon S3). However, I'm getting an error. How I troubleshoot this? Redshift Unload to S3 Location that is a Concatenated String. 5. Unload multiple files from Redshift to S3. 1. Incorrect output when exporting AWS Redshift data to S3 using UNLOAD command. 4. Redshift UNLOAD JSON. Hot Network Questions Are there any original heat shield tiles on any of the retired space shuttles that flew to space? After we added column aliases, the UNLOAD command completed successfully and files were exported to the desired location in Amazon S3. The following screenshot shows data is unloaded in JSON . 1) The cluster was on the same region as the S3 bucket I created. 2) I tried running the UNLOAD command via python, cli, and redshift with the same results. 3) I tried adding a bucket policy for the redshift role. 4) I tried running the unload command using for arns (the redshift role and the s3 role) Finally, I got it to work. What changed?
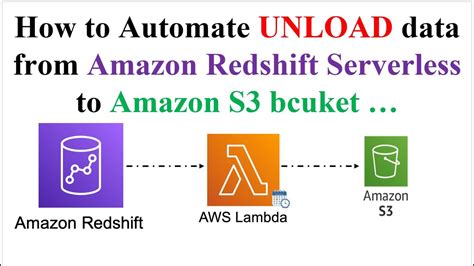
To unload data from database tables to a set of files in an Amazon S3 bucket, you can use the UNLOAD command with a SELECT statement. You can unload text data in either delimited format or fixed-width format, regardless of the data format that was used to load it. On the Redshift Serverless console, open the workgroup you’re using. You can find all the namespaces and workgroups on the Redshift Serverless dashboard. Under Data access, choose Network and security. Choose the link for the Redshift Serverless VPC security group. You’re redirected to the Amazon Elastic Compute Cloud (Amazon .
Redshiftのドキュメントの手順に倣い、RedshiftのデータをS3にUNLOADする。 内容 概要 UNLOADの特徴. クエリの結果をS3にエクスポートする。 ファイルの形式には、テキスト、CSV、Parquet、JSON等指定が可能 デフォルトではパイプ(|)で区切られる。 I would like to unload data files from Amazon Redshift to Amazon S3 in Apache Parquet format inorder to query the files on S3 using Redshift Spectrum. I have explored every where but I couldn't find anything about how to offload the files from Amazon Redshift to S3 using Parquet format. Method 2: Unload Data from Amazon Redshift to S3 in Parquet Format Image Source. Apache Parquet is an Open Source file format accessible for any Hadoop ecosystem. It is designed for efficient flat column data storage compared to row-based formats such as CSV.Unloading a file from Redshift to S3 (with headers) A few days ago, we needed to export the results of a Redshift query into a CSV file and then upload it to S3 so we can feed a third party API. Redshift has already an UNLOAD command that does just .redshift unload to s3 Unloading a file from Redshift to S3 (with headers)unload コマンドの使用方法の例を示します。当 UNLOAD 的目标 Amazon S3 桶与 Amazon Redshift 数据库不在同一个 AWS 区域时,需要 REGION。 aws_region 的值必须与《AWS 一般参考》的 Amazon Redshift 区域和端点中列出的 AWS 区域匹配。 默认情况下,UNLOAD 假定目标 Amazon S3 桶位于 Amazon Redshift 数据库所在的 AWS 区域。When you use Amazon Redshift Spectrum, you use the CREATE EXTERNAL SCHEMA command to specify the location of an Amazon S3 bucket that contains your data. When you run the COPY, UNLOAD, or CREATE EXTERNAL SCHEMA commands, you provide security credentials. s3://mybucket/key000 6.2 GB s3://mybucket/key001 6.2 GB s3://mybucket/key002 1.0 GB Therefore, it will alway add at least the prefix 000 , because Redshift doesn't know what size of the file he is going to output in the first place, so he's adding this suffix in case the output will reach the size of 6.2 GB.
Create an Amazon S3 bucket and then upload the data files to the bucket. Launch an Amazon Redshift cluster and create database tables. Use COPY commands to load the tables from the data files on Amazon S3. Troubleshoot load errors and modify your COPY commands to correct the errors.redshift unload to s3Create an Amazon S3 bucket and then upload the data files to the bucket. Launch an Amazon Redshift cluster and create database tables. Use COPY commands to load the tables from the data files on Amazon S3. Troubleshoot load errors and modify your COPY commands to correct the errors.
How to escape quotes inside an AWS redshift unload statement? Full disclosure, I know one way to do this but haven't seen a good link or SO question so figured I'd post one for others benefit. sql; amazon-web-services; amazon-redshift . Load data into Amazon Redshift from S3 with quotation marks. 1. Redshift not recognizing quoted .
No there is no way to do that when using the HEADER option, because Redshift does not have case sensitive column names. All identifiers (table names, column names etc.) are always stored in lower case in the Redshift metadata. You can optionally set a parameter so that column names are all returned as upper case in the results of a .
RedShift Unload to S3 With Partitions - Stored Procedure Way. August 27, 2019 • aws, redshift, s3, sql. Redshift unload is the fastest way to export the data from Redshift cluster. In BigData world, generally people use the data in S3 for DataLake. So its important that we need to make sure the data in S3 should be partitioned.
redshift unload to s3|Unloading a file from Redshift to S3 (with headers)
PH0 · sql
PH1 · Unloading data to Amazon S3
PH2 · Unloading a file from Redshift to S3 (with headers)
PH3 · UNLOAD examples
PH4 · UNLOAD Redshift Table to S3 and Local
PH5 · UNLOAD
PH6 · Redshift UNLOAD Command
PH7 · Export data from AWS Redshift to AWS S3
PH8 · Export JSON data to Amazon S3 using Amazon
PH9 · Amazon Redshift to S3: 2 Easy Methods